SCARF: Stereo Cross-Attention Radiance Fields
Using a cross-attention mechanism for rendering in Stereo Radiance Fields
[1]
In Stereo Cross-Attention Radiance Fields (SCARF), we explore adding attention-based techniques to Stereo Radiance Fields [1]. In recent years, there have been great advances in attention/transformer-based techniques which allow for faster training and consistent architecture across models. Although transformer-based techniques have already been applied to the original NeRF paper [2] [3], we aim to apply it to the SRF paper, which, instead of learning the scene, aims to emulate and learn multi-view stereo. Their method allows for training with sparse views (only 10 instead of 100), and also learns how to perform multi-view stereo correspondences rather than learning only a single scene, thus allowing for rendering of novel scenes in a single pass (with fine-tuning).
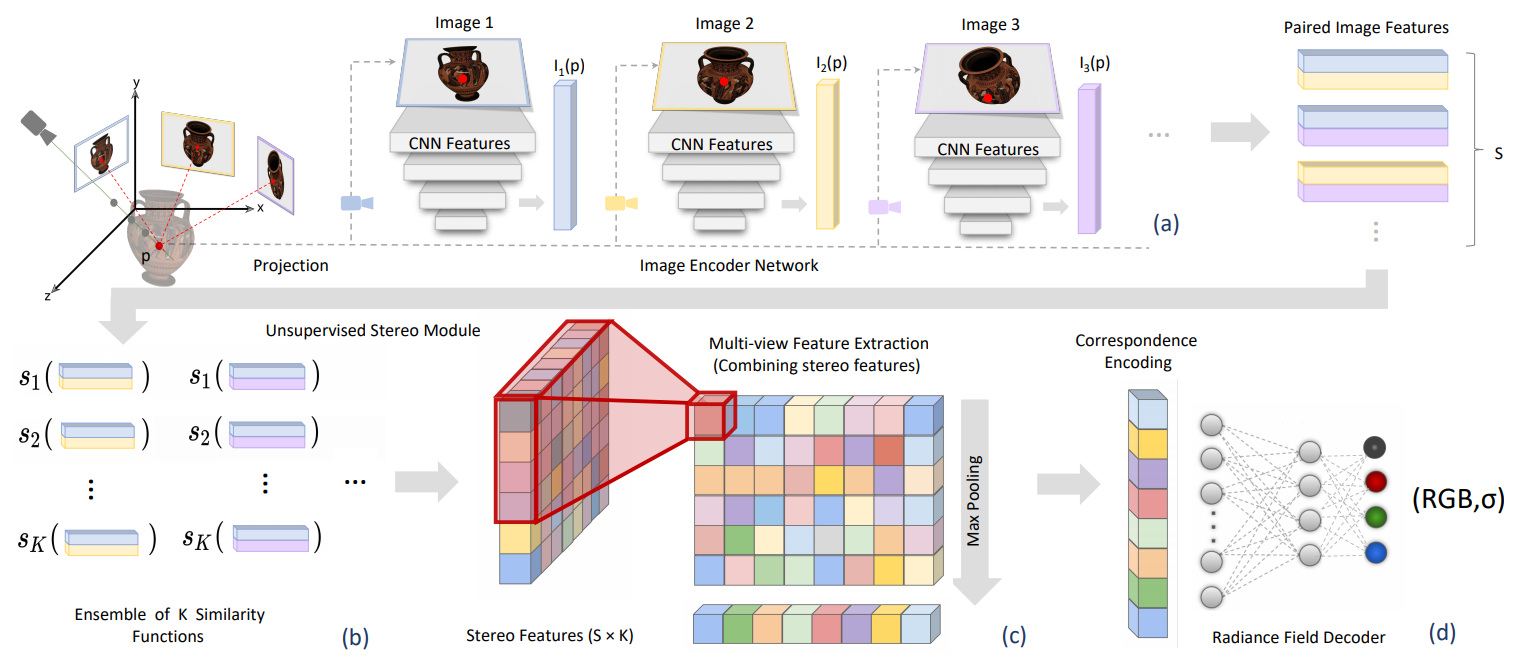
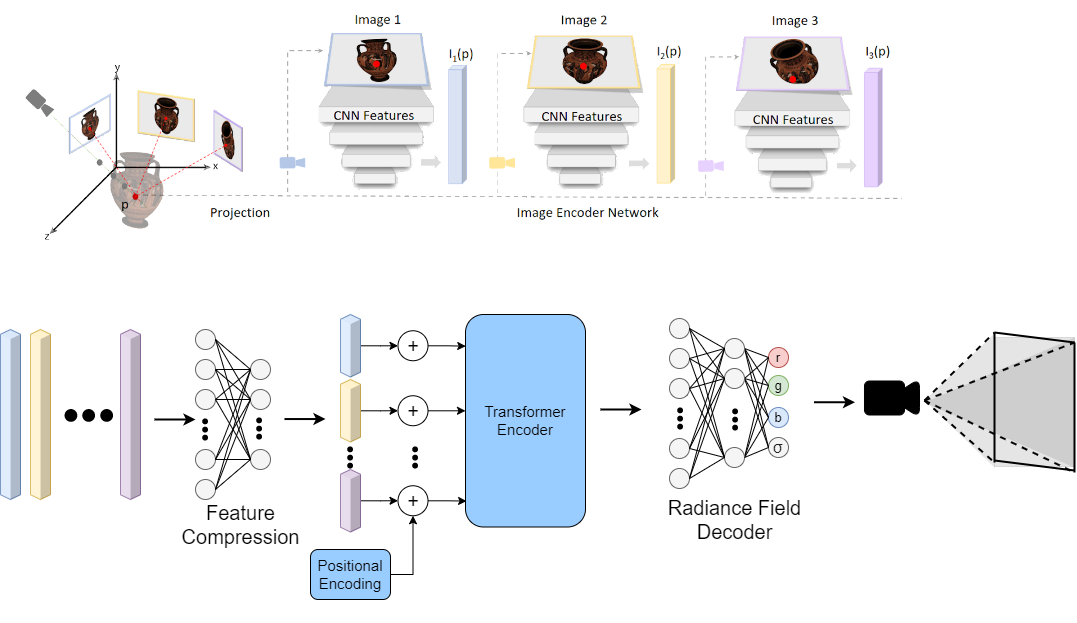
First, we investigated the architecture from the SRF paper shown in Figure 1. We hypothesized that the feature pairing, unsupervised stereo module, multi-view extraction, and correspondence encoding could all be replaced by a (cross-)attention mechanism. Practically, this was implemented in PyTorch using a transformer encoder, borrowing from the ideas of the Vision Transformer (ViT) [4]. This makes intuitive sense, because stereo is about finding correspondences between different features in the image, the process of which can be reframed as cross-attending across features. This drastically simplified our architecture shown in Figure 2.
After the image features layer, we first feed into an image feature compression network. This helped reduce the number of parameters that the transformer network needed to learn. See Experiment 1 under the Results section for justification and different techniques that were attempted.
After feature compression, we feed a sequence of feature vectors (one per view) into a transformer encoder, which aims to learn the relation between different views. The feature vectors were positionally encoded in the same way as ViT [4] to track which image each feature set came from. We experimented with various different hyperparameters for this transformer encoder to get good results. We attempted different numbers of heads in Experiment 2 and different number of transformer layers in Experiment 3. Max-pooling is run over the output images to preserve the most important features from each image.
Finally, we pass the output of the transformer layer through the fully connected "Radiance Field Decoder" (2 FC layers), which results in an RGB-σ value for each 3D point.
First, we experimented with two different techniques in order to reduce the model size. First, we attempted to use a reduced image feature extraction network. This reduced network used half the number of channels for each layer, and dropped the last two convolution layers from the SRF paper. This significantly reduced the number of parameters that the transformer needed to learn.
The other technique we used to reduce model size was an image feature compression layer, which reduces the size of the image features. This technique both reprojects into a space to help the transformer learn, and also allows for some learning of relation between multi-scale features before the transformer encoder.



Our first experiment was to see the trade-offs between no compression, reduced features, and image compression. We found that the network was not able to learn quickly with the large transformer size. It did not learn a significant amount of information in the scene by iteration 50k, as shown in Figure 3a. Between feature compression and network reduction, we found that the feature compression was able to do a much better job at learning quickly, reconstructing finer details like color, and minimizing artifacts
For the transformer, we first varied the nubmer of heads used in each cross attention layer. We held the number of layers constant at 2, and attempted 8, 16, and 32 heads.


As can be seen in Figure 4, increasing the number of heads was significant in improving the quality of the results, in particular the detail and vibrancy of colors. For example, the rendering with only 8 heads (Figure 4a) looks faded, but the rendering with 16 heads (Figure 4b) looks much more vibrant. We begin to see distinct colors for the different houses and the umbrellas on the patio are yellow as they should be. However, some of the colors still seem faded, and there are some "blurring" artifacts near the patio area where the umbrellas are.
The rendering with 32 heads (Figure 4c) looks even better, and is our best result overall. The house and patio colors look much more vibrant and closer to the ground truth. There is also increased detail for the windows, roofs and other objects in the scene. While the model is larger and takes longer to train on its own, using pretrained weights from previous heads allowed us to reduce training time significantly.
The results make intuitive sense, because increasing the number of heads increases the number of feature subspaces to cross-attend to. This may allow the model to learn more complex and different relationships between features, and therefore increases the level of detail and color vibrancy in the rendered scene.
We then varied the nubmer of transformer cross attention layers. We held the number of heads constant at 16, and attempted 2 and 4 layers.

Finally, we added more layers to the transformer. We transfered the weights from the 2 layer 8 head model and found that the network performed even better with 4 layers. The performance of the 4 layer 16 head model is comparable to the performance of the 2 layer 32 head model.
As aforementioned, we discovered that the 2 best architectures were 2 layers 32 heads and 4 layers 16 heads. We then tried rendering a pose of different scene (Scene 106) from the DTU dataset. The scene pictures a statuette of two textured doves. The results are shown in Figure 6 below. It is noted that the quality of the renderings for both architectures is pretty good, and are comparable to one another, similar to the results for Scene 23.
This scene presents a different challenge for the network, as the doves are textured and have a lot of detail. Similar to SRF [1], our network is able to capture the detail of the doves, and the colors are also vibrant. As noted in the SRF paper, the original NeRF paper is unable to capture the detail of the doves. However, our results are comparable to the non-finetuned results of the SRF paper, although results may improve with fine-tuning (we have not tested fine-tuning of our models yet).



More experimentation is needed to understand the following:
You can view compiled time-lapse animations/videos of the scene learning for any of the presented experiments by clicking the red buttons near the captions. This is applicable for Figures 3, 4 and 5 above. The button below toggles visibility for all of them.
For the transformer architecture of 2 layers and 32 heads, Scene 106 (the dove scene) was rendered in 3D using Pyglet, and exported as a HTML file rendered with threejs. It can be viewed here.
Unfortunately, the 3D rendering of the scene is not very good, with some errors along the rays. This could be due to the model not being fine-tuned, or the model not being trained for long enough (we have trained for less than half the number of iterations that SRF used in their model).

